
")
KI-Grundlagen auf einen Blick
Das steckt hinter AI, ML, DL und LLM


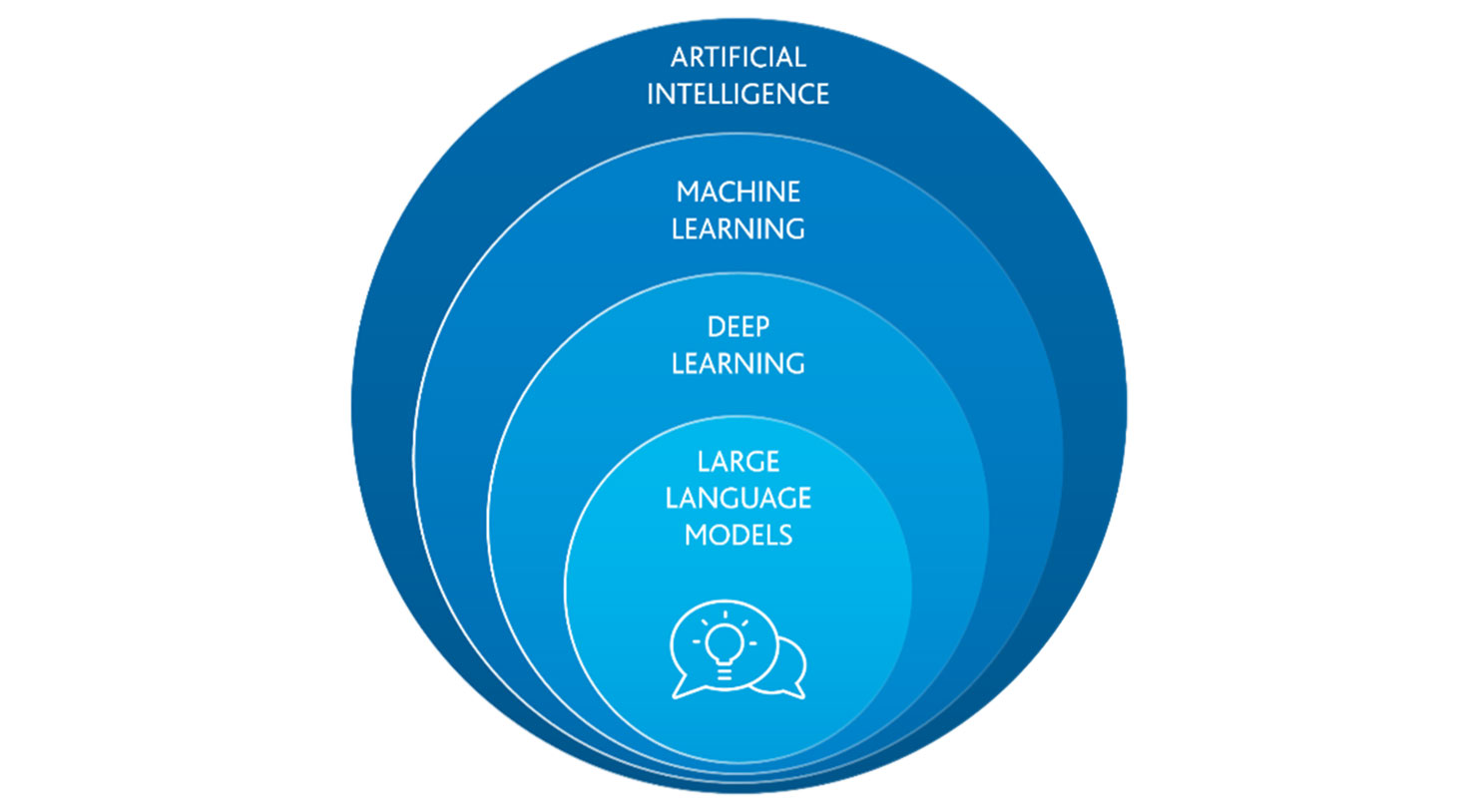
Durch die beeindruckenden Ergebnisse, die Large Language Modelle wie ChatGPT erreichen, hat Künstliche Intelligenz (KI) einen enormen Aufschwung erlebt. KI hält nach und nach Einzug in viele Bereiche unseres Lebens und verändert so die Art und Weise wie wir tagtäglich arbeiten. Um die aktuellen Large Language Modelle und deren mögliche Anwendungen besser zu verstehen, ist es sinnvoll, mit einer kurzen Einordnung zu starten. So hängen Artificial Intelligence (AI), Machine Learning (ML), Deep Learning (DL) und Large Language Modell (LLM) zusammen.
Artificial Intelligence
Der Begriff Artificial Intelligence (zu Deutsch: Künstliche Intelligenz) bezeichnet einen Bereich der Informatik, der sich mit der Erschaffung und Entwicklung von Maschinen oder Software beschäftigt. Diese Anwendungen sind in der Lage, Aufgaben durchzuführen, die normalerweise menschliches Denken erfordern. Im Kontext des Digital Workplace mit Microsoft 365 gehören dazu zum Beispiel Aufgaben wie die Erstellung von Präsentationen, das Verfassen von E-Mails oder auch die Beantwortung von Fragen auf Basis von bestimmten Daten.
Maschine Learning
Das Ziel von Machine Learning, ein Teilgebiet der Künstlichen Intelligenz, ist es eine Beziehung zwischen Eingabe- und Ausgabe-Daten herzustellen. Machine Learning kann Probleme lösen, die zu komplex sind, um sie in einfache Regeln zu überführen, für die aber viele Beispieldaten existieren. Diese Beispieldaten werden genutzt, um ein Modell zu trainieren, welches im Anschluss auch auf neue, unbekannte Daten angewendet werden kann. Häufige Beispiele sind die Erkennung von Kreditkartenbetrug, Diagnoseverfahren oder Texterkennung.
Deep Learning
")
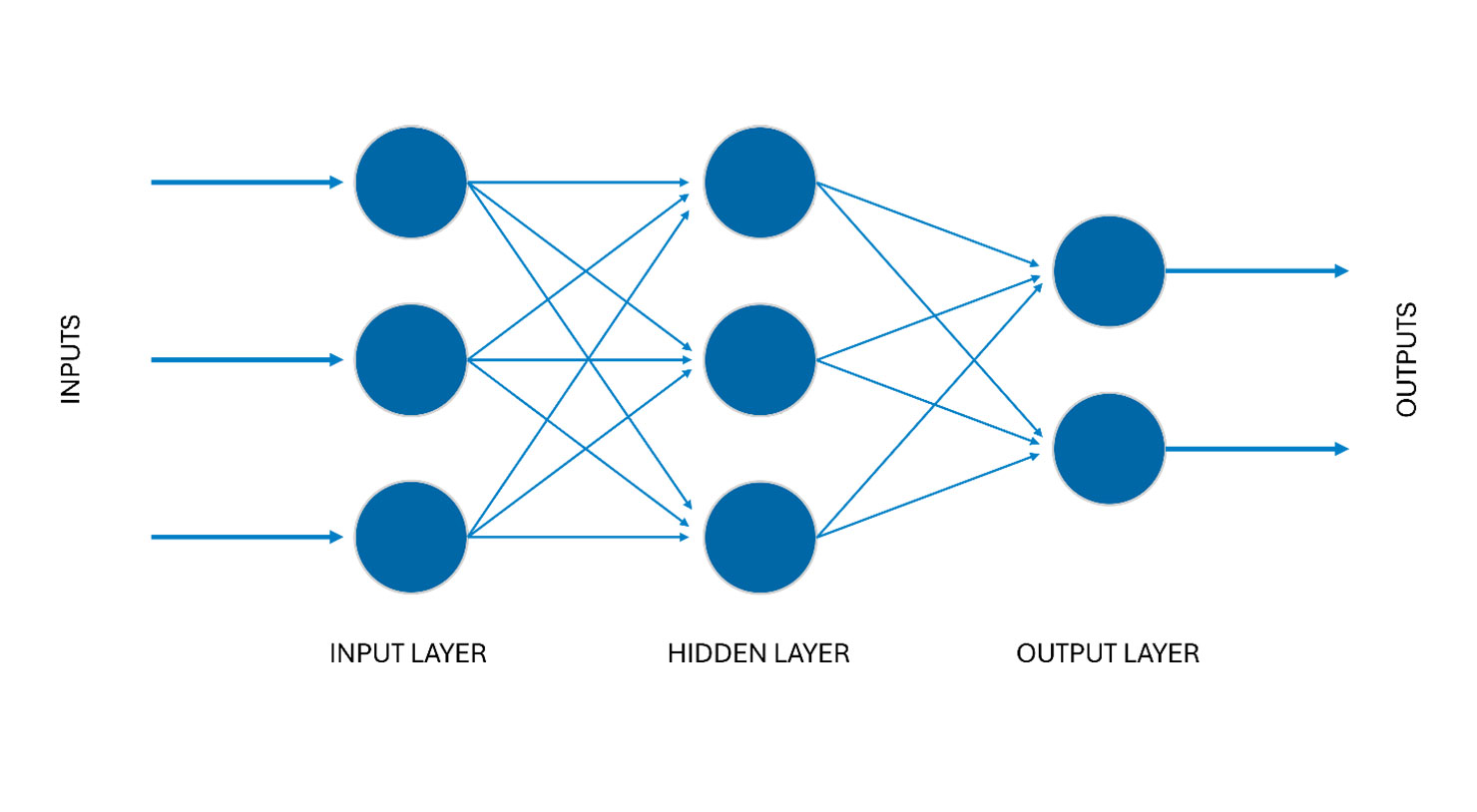
Deep Learning treibt die Idee des Machine Learnings weiter und überträgt sie auf weitaus komplexere Anwendungsfälle. Hierzu werden mehrschichtige, künstliche neuronale Netze verwendet. Wie beim Machine Learning müssen auch diese Modelle zunächst mit vielen Daten trainiert werden. Das Ziel bleibt aber die Vorhersage von Ausgabewerten auf der Basis von Eingaben.
Large Language Models
Large Language Models sind Deep-Learning-Modelle, die Sprache verstehen und erzeugen können. Sie werden unter Nutzung enormer Rechenleistung mit einer großen Menge an Daten trainiert. Das Ziel eines Large Language Models ist es, das nächste Wort in einer bestehenden Kette von Wörtern vorherzusagen. Wie schon bei Deep Learning und Machine Learning geht es also darum einen Zusammenhang zwischen Eingabeparametern (eine Liste von Wörtern) und gewünschten Ausgaben (dem nächsten Wort) herzustellen.
Der wohl bekannteste Vertreter der LLMs ist ChatGPT in seinen verschiedenen Versionen.
Generative pre-trained transformer
Das GPT in ChatGPT steht für generative pre-trained transformer und beschreibt die drei Hauptkomponenten des Modells:
Generativ bedeutet, dass das Modell in der Lage ist, neue Texte zu erzeugen, die auf einem gegebenen Eingabetext basieren oder diesen fortsetzen. Basierend auf Wahrscheinlichkeiten ermittelt das Model den nächsten Worttoken, der dem Eingabetext hinzugefügt werden soll. Das Resultat läuft dann erneut durch das Modell.
Pre-trained bedeutet, dass das Modell vorab mit einer großen Menge an Textdaten trainiert wurde, um eine allgemeine Sprachrepräsentation zu erlernen. Das pre-training ermöglicht es dem Modell, verschiedene linguistische Muster und Zusammenhänge in natürlichen Sprachen zu erfassen, jedoch ohne eine spezifische Aufgabe zu erfüllen.
Transformer bezeichnet die eigentliche Architektur des neuronalen Netzes. Ein Transformer besteht aus zwei wesentlichen Komponenten: Einem Encoder, der den Eingabetext in eine abstrakte Darstellung umwandelt, die die Bedeutung und Beziehung von Wörtern erfasst und einem Decoder, der das Ergebnis des Encoders nimmt und daraus den Ausgabetext erzeugt.
Pre-training und Instruction Training
Durch das pre-training erlangt das Modell zwar sehr viel Wissen, ist aber nicht in der Lage, konkrete Aufgaben zu erfüllen. Zum Beispiel muss das Modell noch lernen, wie es auf eine Frage mit einer klaren, genauen Antwort reagieren kann. Dazu braucht es ein weiteres Training, das instruction training oder instruction fine-tuning genannt wird. Die Trainingsdaten sind hierbei viel kleiner, enthalten aber gezielte Beispiele von Aufgaben und erwarteten Ausgaben.





Verfasst von